We Asked 1,000 Humans and ChatGPT Pretending to Be 1,000 Humans The Same Questions… Here’s What Happened
As a company that helps organizations learn from survey response data, we have been spending more time exploring ideas that are at the forefront of market research.
This exploration is the first step in our journey to understanding the capabilities and limitations of synthetic data. There are undoubtedly several ways to refine the initial responses, but such adjustments fall beyond the scope of this preliminary evaluation.
TL;DR
- We ran a survey to learn about demographic and political orientation on two populations
- Population 1: 1,000 Random Americans via Prolific.com
- Population 2: ChatGPT Generated Data to Represent 1,000 Random Americans
- Across almost all variables, we found that the ChatGPT sample diverges from the human sample in important ways.
- Key Finding: When we began to examine relationships between variables we immediately found a strong inconsistency: unlike our sample and the general empirical reality of 2024, the responses generated by ChatGPT showed no association between reported preferred political party and preferred next president of the United States.
Setting Up the Data Comparison
Using Prolific, a partner software, we surveyed 1,000 Americans with the following targeting criteria:
- Residing within the United States
- Standard (random) sampling
- No limits on age, race/ethnicity, gender or other demographic quotas.
- Only one response allowed per participant
In parallel, we asked ChatGPT to simulate the same number of responses using the following prompt:
Please generate a synthetic dataset that simulates responses from 1,000 U.S. citizens to a survey.
The dataset should be in CSV format, with each row representing a different respondent and each column representing a response to a specific survey question.
The survey structure and questions are included in the attached JSON file, which has been exported from the Checkbox.com platform.
Instructions for Data Generation:
- The data should adhere closely to actual U.S. demographic statistics for each question.
- Ensure realistic correlations between variables (e.g., older respondents are more likely to be retired, higher education levels are associated with higher income, etc.).
- Include a header row with the names of each question as column titles.
- Save the data in a CSV format.
To see how well AI-generated data could stand-in for human insights, the survey covered three areas:
- Control: A question as simple as asking the respondent to choose a random number between 1 and 100 can highlight interesting differences between two populations.
- Demographics: Questions such as gender, age, race/ethnicity, education, and income allow us to assess how representative a population is and how it aligns to U.S. demographics.
- Political Alignment: The talk of the town this election season, we asked these questions to analyze correlation with the demographics answers. This is where an LLM could have issues as opposed to just answering questions to an average distribution.
Here are the most interesting insights revealed by the experiment - some will surprise you.
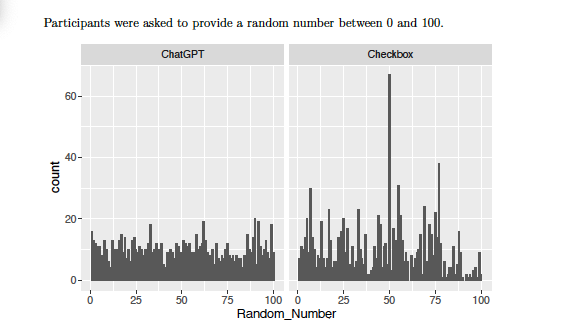
Control Question: AI’s “Perfect” Randomness vs. Actual Human Behavior
Asking participants a simple control question— choose a number between 1 and 100—revealed a key distinction between their answers and AI’s. Humans showed predictable biases, often choosing numbers like 50 or 77, while ChatGPT's responses were statistically random. Human beings don’t make purely random selections, often choosing numbers with cultural significance or personal meaning such as birth dates, family or lucky numbers. This subtle yet important difference reinforces the unique complexity of human behavior, a nuance AI struggles to capture and fully replicate. Therefore the data it produces lacks the personal touch that adds depth to human data.
A Demographic Deep Dive
When we looked at demographic responses, the discrepancies between ChatGPT and Human Responses widened further.
Marital Status
There are notable differences between the human sample and ChatGPT, with the former having a higher proportion of people in domestic partnerships. ChatGPT is drawing on generalized statistical information rather than capturing real human variability. To be fair, this is what we asked the ChatGPT to perform, but it’s always interesting to see the contrast. One way to combat these biases is to work with quotas for respondents on the human panel side of things.

Children or Dependents
ChatGPT had a higher proportion of respondents with children compared to the human sample. There isn’t much to learn here.

Employment Status
We can see that the panel respondents were more likely to be unemployed and looking for work, whereas ChatGPT reported significantly more Retired persons. This makes sense when you consider the context of each data set. According to data from the U.S. Census Bureau, about 1 in 6 of Americans are of retirement age, which ChatGPT was aligning to general U.S. Population distributions. Likewise, people on Prolific are probably more likely to be in-between jobs and looking for supplemental income.

Household Income
The human sample reports 8.7% of respondents earning less than $20,000, whereas the ChatGPT data places the majority of respondents in this lowest income bracket and strictly decreases percentages as income increases:

In this case, Prolific's respondents much more closely resemble the 2023 Income data from the U.S. Census Bureau (Table A-2), which shows concentrations of American households between $50,000 to $149,999 and interestingly 14.4% of households earning $200,000 or more.
Education Level
Overall, the Prolific data set reported higher education levels than ChatGPT, with over 50% reporting a Bachelor’s Degree or higher. As of 2022, the U.S. Census Bureau (Table 2-2) reported that ~37.6% of Americans held at least a Bachelor’s:

Race/Ethnicity
ChatGPT's distribution of race/ethnicity produces significantly more White/Caucasian respondents and fewer Hispanic/Latino and Black/African American respondents than the human sample:

With so many categories, some of which with too few responses, it is prohibitive to run a chi-square test as a whole; however, we can at least test whether the proportion of the “White” respondents differs:

This is important feedback when considering the next iteration of our testing, as question design has a large impact on the type and reliability of analysis one can conduct.
Population Distribution by State
There is a statistically significant difference between ChatGPT’s distribution and the distribution in the human sample. Surprisingly, ChatGPT reported a roughly uniform distribution across all 50 states, whereas the human sample reported higher response counts from high population states such as California, Texas, Florida, and so on. It’s clear that the human sample is a more representative distribution, so this is something that would need to be accounted for in further AI samples:

Political Identity
ChatGPT's responses lean more conservative than the human responses which show a stronger liberal leaning. The AI responses also reflected a higher number of respondents who identify as libertarian and moderate. It’s interesting that the human sample had such a high concentration of liberal respondents. Understanding and controlling for these potential biases in your population is important. If this would be material to the analysis, setting quotas and proper targeting will be needed in subsequent panels:

Political Party Alignment
Unsurprisingly– given the above– a significantly larger proportion of human respondents identify as Democrat. ChatGPT also has a higher tendency to avoid political identification, as shown in the higher number of “Prefer not to say” responses:

Stance on Government Involvement
Both samples reported a similar distribution in that the majority of respondents want at least a moderate level government involvement, but differ in how strong that involvement should be. Human responses strongly favor moderate (“some”) involvement while ChatGPT reported the majority desiring strong involvement. Understanding this bias towards extreme opinions is important to note when considering using synthetic data for real-world exercises:

Preferred Next President
Coming as no surprise following the Political Identity and Party Alignment responses, the human sample reported a statistically significant preference for Kamala Harris to be the United States’ next president. Of course, being so close to election night in the United States, using synthetic data would be a misstep given the volatile nature of the next 48 hours. However, this again speaks to the leaning of the human sample population towards the Left, which needs to be accounted for:

And a special shout-out to all of the humans (not shown above) who responded with various flavors of “anyone else,” “neither,” or desiring the abolition of elections as a whole! As you can see by the sample sizes in this section, we only included the pre-selected options.
Key Finding
Each point above shows clear discrepancies between the human generated dataset and the AI-generated dataset. Although that might feel expected in aggregate, the devil is in the details. As you drill down into the full response set from ChatGPT, you see where things break down. The expected identities of their fictitious respondents are not consistent with how we experience people in the real world.
For example, we explored relationships between variables, trying to assess whether the relationships found in the human sample can also be found in the ChatGPT sample. The question most representative of our findings was how the political party mapped to the respondent’s desired next president. First, in our human population from Prolific:

As expected, there is a strong association between the reported political party and preferred next president, with Republicans preferring Donald Trump and Democrats preferring Kamala Harris.
The table below shows that this is clearly not the case for the ChatGPT sample. For example, of the rows “preferring” Donald Trump, a whopping 38% are also supposed to be “Democrats”, and only 31% are “Republicans”:

It is our finding that ChatGPT can do a great job of large, anonymous data sets, but has a really hard time creating rich representative profiles of true human responses. This becomes evident the more you play with the datasets and dive into each respondent to see how it checks out.
Conclusion
This was an extremely fun project to work on. The idea was able to be put into action within a matter of days for a total budget of $500. With all of the learnings, we came up with the top 3 improvements that we would have loved to make after getting our results back:
- More Data: We wish we had 1,000 respondents at each of the state levels (50,000 total) to do better prediction for the Electoral College voting system. Data people always want…more data.
- Better Prompt/Targeting: Learning how ChatGPT handled this scenario allows us to perform some prompt engineering. Likewise, we can define better targeting on Prolific to ensure we have the most representative human sample, accounting for potential biases.
- Deeper Analysis: We played around with amplification of responses, changing how we interacted with ChatGPT and dove into the human generated responses. In all cases, we were left with more questions than answers. We want to plan for more time in the future to go deeper on analysis.
There is a big community in which we can share more exploratory analysis like this in the future. Hopefully it will inspire your next great survey on Checkbox.
If you’d like to learn more about how you can use Checkbox with Prolific to send your research surveys out to qualified panel participants– check us both out at Prolific.com and Checkbox.com



Contact us
Fill out this form and our team will respond to connect.
If you are a current Checkbox customer in need of support, please email us at support@checkbox.com for assistance.
